Multitasking v MicroPythonu na ESP32
Při vývoji aplikací pro ESP32 s MicroPythonem se občas můžeme setkat s potřebou provádět více úloh současně. Jako příklad si můžeme představit webový server, který kromě vyřizování požadavků klientů zároveň čte data z nějakých senzorů, ovládá motor nebo provádí jakoukoliv další komunikaci. V klasickém Pythonu bychom pro vyřízení takové „paralelní“ činnosti mohli využít vlákna (threading) nebo asynchronní programování (asyncio). Když to zvládá Python, napadne nás, zda bychom nemohli podobné služby požadovat i od MicropPythonu? Mohli! Ale jak už to bývá, MicroPython má svá specifika, která musíme vzít v úvahu. (A ten pro modul ESP32 zvláště!)
Scénář multitaskingu (server s čidlem DHT11)
Zkusíme si ilustrovat vyřizování více úloh najednou na příkladu webového serveru, který bude zároveň načítat nějaký senzor a vyřizovat síťovou komunikaci. Využijeme znalostí nabytých v předešlých článcích. Jak v MicroPythonu naprogramovat modul ESP32 jako webový server jsme si ukázali v článku Jednoduchý server na ESP32 v MicroPythonu, ovládání a načítání čidla DHT11/22 jsme zase poznali v článku ESP32 a čidlo DHT11/22 v MicroPythonu. Scénář našeho počínání tedy bude jasný: Naprogramujeme náš modul ESP32 tak, aby běžel jako jednoduchý webový server, který současně periodicky čte hodnoty z čidla DHT11 a vyřizuje požadavky klientů.
Nejdříve k modulu ESP32 připojíme čidlo DHT11. Jeho napájecí piny (+ a GND) připojíme k pinům modulu ESP32, na kterých je k dispozici napětí 3,3 V a zemnění GND. Signálový výstup čidla můžeme připojit k jakémukoliv pinu modulu ESP32, který lze použít jako digitální vstup – my použijeme např. GPIO 4. Pokud používáme čidlo holé, tedy nikoliv kit na malé destičce DPS, je dobré připojit mezi pin + (napájecí napětí) a signál (S) pull-up rezistor. Více o připojení čidla DHT11 k modulu ESP32 najdete ve zmíněném předešlém článku ESP32 a čidlo DHT11/22 v MicroPythonu, takže to zde nyní jen „odbudeme“ obrázkem:
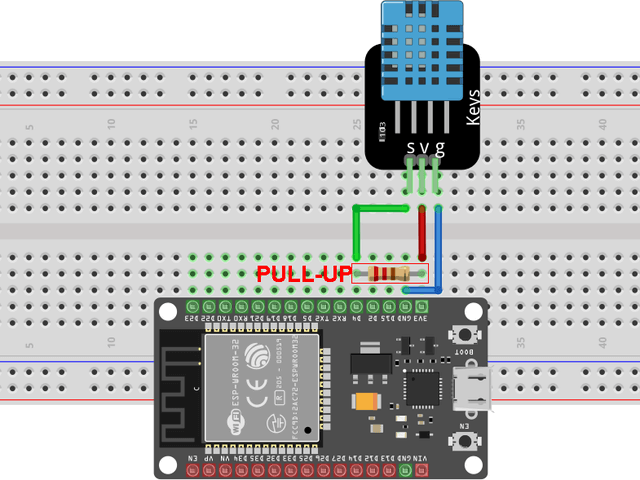
Máme-li čidlo připojené, můžeme se pustit do vytvoření programu měřicího serveru s nádechem multitaskingu.
V principu máme dvě možnosti:
- Řešení s vlákny – modul
_thread - Řešení s asynchronním přístupem – modul
asyncio
A. Práce s vlákny
Programování pomocí vláken (nebo threading) je technika, která umožňuje provádění více úkolů současně v rámci jedné aplikace. Vláknem se rozumí nejmenší jednotka vykonávání v rámci procesu. Každý proces v operačním systému může mít několik vláken, která sdílejí stejné prostředky, jako je paměť a otevřené soubory, ale každé vlákno běží nezávisle a má vlastní instrukce pro vykonání. Vláknům říkáme také „lehké procesy“, protože jsou součástí většího procesu a nevyžadují tolik systémových prostředků jako samostatné procesy.
Programování s vlákny znamená, že aplikace rozděluje vykonávání úloh na více částí, které se mohou provádět paralelně. Tato metoda je zvlášť užitečná pro aplikace, které potřebují provádět více operací současně, například:
- Zpracování více požadavků na serveru
- Paralelní výpočty pro urychlení složitých algoritmů
- Interaktivní aplikace, které musí reagovat na uživatelský vstup a zároveň provádět jiné operace na pozadí
Abychom tuto techniku zvládli, musíme se zaměřit na:
- Vytvoření vláken: V rámci programu můžete vytvořit vlákna, která budou vykonávat různé části kódu. Každé vlákno provádí svou vlastní instrukci, což může znamenat například obsluhu různých částí uživatelského rozhraní nebo paralelní zpracování dat.
- Paralelismus: Vláknům se může přiřadit různé procesory nebo jádra (pokud je dostupná vícejádrová architektura procesoru). To znamená, že každý úkol může běžet na jiném jádru procesoru, čímž se zvyšuje výkon aplikace.
- Synchronizace: Vláka mají přístup ke společné paměti a prostředkům. Pokud více vláken čte nebo zapisuje do stejného úseku paměti, může dojít k problémům s race condition (soutěžení vláken o přístup k prostředkům). Proto je třeba synchronizovat vlákna, například pomocí zámků (locks), semaforů nebo podmínek (condition variables), aby se zajistilo, že k těmto prostředkům přistupují správně.
Tolik obecná teorie, nyní se vrátíme zpátky na zem, tedy spíše přesněji řečeno do prostředí MicroPython, a to konkrétně na modulu ESP32:
- Modul ESP32 (aspoň zde používaný kit) je sice osazen dvoujádrovým procesorem, ale MicroPython (na jakémkoliv modulu ESP32!) vždy používá pouze jádro jediné (core 0)– a to i pro běh kódu v rámci různých vláken. To znamená, že i když se vlákna spustí, běží stále na stejném jádru. Takže vlákna v MicroPythonu na modulu ESP32 nejsou skutečně paralelní, ale i tak se na první programátorský pohled vlastně tak chovají.
- Synchronizace vláken v MicroPythonu běžícím na modulu ESP32 není tak snadná jako v některých plnohodnotných operačních systémech, protože MicroPython je zjednodušenou verzí Pythonu pro mikrořadiče, která není navržena pro složité paralelní operace a multithreading. Přesto poskytuje určité možnosti pro správu vláken a synchronizaci, i když s některými omezeními a odlišnostmi oproti tradičním operačním systémům (v tomto článku se tomu však věnovat nebudeme).
Použití modulu _thread
Modul _thread v MicroPythonu slouží k implementaci základního vícevláknového programování (multithreading) na mikrokontrolérech. Tento modul umožňuje spouštět více vláken (threads) současně, což může být užitečné v případech, kdy chcete paralelně provádět různé úkoly na více vláknech, každý s vlastní nezávislou činností. Jinými slovy tento modul umožňuje vytvořit a spustit vlákna, která poběží nezávisle na hlavním programu (a to i když vlákna poběží „jen“ na stejném jádře jako hlavní program).
Modul _thread v MicroPythonu na platformě ESP32 má některé specifické vlastnosti, které jej odlišují od standardní implementace _thread v běžném Pythonu. To je dobré si uvědomit zejména, pokud čteme návody pro obecný Python nebo MicroPython nebo chceme přenést nějaký program na modul ESP32.
Základní prvky modulu _thread: (pro ESP32)
_thread.: Spustí nové vlákno, které vykonává funkcistart_ new_ thread( func, args, kwargs, stack_size) funcs argumentyargsakwargs. Volitelně můžeme nastavit velikost zásobníku pro vlákno pomocí parametrustack_size._thread.: Vrací identifikátor aktuálního vlákna. Tato metoda je užitečná pro sledování a identifikaci vláken při práci s více úkoly běžícími současně.get_ident() _thread.: Vytvoří nový zámek (lock), který lze použít pro synchronizaci mezi vlákny. Tento zámek je užitečný pro zabránění souběžnému přístupu ke sdíleným datům.allocate_ lock() _thread.: Umožňuje nastavit velikost zásobníku pro nově vytvářená vlákna. Tato funkce je specifická pro ESP32 a není běžně dostupná na jiných platformách.stack_ size()
- Poznámka:
- Metoda
_thread.exit(), která má za úkol ukončit vlákno (a je tedy často jako metoda modulu_threadv různých přehledech uváděna), není v MicroPythonu pro ESP32 implementována! Využívá se tedy faktu, že vlákna končí, když jejich funkce dokončí svůj běh (nebo když dojde k výjimce). Ukončení vláken se tedy musí řídit kontrolou v rámci samotné funkce vlákna.
V následujícím příkladu si tedy zkusíme vytvořit náš výše vytyčený ukázkový příklad, tj. webový server, který běží v hlavním vlákně, zároveň se v samostatném vlákně budou pravidelně načítat hodnoty z čidla DHT11.
Kód programu:
import network
import socket
import _thread
import time
from machine import Pin
from dht import DHT11
# Připojení k Wi-Fi
SSID = "TvojeWiFi"
PASSWORD = "HesloWiFi"
sta_if = network.WLAN(network.STA_IF)
sta_if.active(True)
sta_if.connect(SSID, PASSWORD)
while not sta_if.isconnected():
pass
print("Připojeno:", sta_if.ifconfig())
# Inicializace DHT11
dht_pin = Pin(4) # Použijeme správný GPIO pin
dht_sensor = DHT11(dht_pin)
# Globální proměnné pro ukládání dat
temperature = None
humidity = None
def read_dht():
"""Vlákno pro pravidelné čtení DHT11."""
global temperature, humidity
while True:
try:
dht_sensor.measure()
temperature = dht_sensor.temperature()
humidity = dht_sensor.humidity()
print(f"Naměřeno: {temperature}°C, {humidity}%")
except Exception as e:
print("Chyba při čtení DHT11:", e)
time.sleep(2) # Čteme každé 2 sekundy
# Spuštění druhého vlákna
_thread.start_new_thread(read_dht, ())
def handle_request(conn):
"""Obsluha HTTP požadavků."""
request = conn.recv(1024)
print("Požadavek přijat:", request)
response = f"""HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Teplota: {temperature} °C
Vlhkost: {humidity} %
"""
conn.send(response)
conn.close()
# Spuštění webového serveru
def run_server():
"""Spustí jednoduchý HTTP server na portu 80."""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(("0.0.0.0", 80))
s.listen(5)
print("Server běží na portu 80")
while True:
conn, addr = s.accept()
print("Připojení od:", addr)
handle_request(conn)
# Spustíme server v hlavním vlákně
run_server()
Podíváme-li se na program, vidíme, že se skládá ze tří základních částí:
- Připojení k existující Wi-Fi síti – modul ESP32 je nastaven do režimu STA (stanice), pomocí přístupových údajů se přihlásí k existující Wi-Fi síti. Jak nastavit modul ESP32 pro přístup k Wi-Fi se nyní již nabývat nebudeme – případný zájemce se musí podívat do článku ESP32 – jak na Wi-Fi v MicroPython?.
- Obsluha čidla DHT11 – Obsluha měřicího čidla je koncipována do samostatné funkce
read_dht(), kterou budeme pouštět v samostatném vlákně. Kromě nastavení týkajícího se samotného měření a komunikace čidla s modulem ESP32 je zde nutné vyřešit sdílení naměřených hodnot vlákna měřicího s vláknem serverovým. K tomuto účelu jsou v programu globální proměnnétemperatureahumidity. - Webový server – tato část je rozdělena do dvou funkcí. Jedna se především zabývá obsluhou dotazů připojených klientů (nekonečná smyčka ve funkci
run_server()), druhá vytváří odpověď, kterou server klientům odesílá (handle_). Funkcerequest() run_server(), jak její název asi napovídá, se stará i o samotné prvotní nastavení serveru.
Podíváme-li se na všechny tyto hlavní části programu, vidíme kód, který je čtenáři předešlých článků věnovaným programování ESP32 v MicroPythonu dobře znám! Asi nás tedy napadne otázka: „A kde je, sak*a, tedy ten slibovaný multitasking!“
Tak jako se ďábel skrývá v detailu, tak i zde se to celé „divadlo“ odehraje na jediné řádce programu:
_thread.
Metoda start vytvoří a spustí samostatné vlákno pro zadanou funkci (název je prvním argumentem) s definovanými vstupními parametry v druhém parametru (v našem případě je zde prázdná závorka). Od tohoto příkazu se v samostatném vlákně spustí funkce read_dht.
- Důležitá informace!
- Je třeba vědět, že vytvořením samostatného vlákna pro běh dané funkce nezařídí její opakované spouštění. Pokud funkce spuštěná ve svém vlákně proběhne a skončí, dojde prostě k jejímu ukončení a i zrušení daného vlákna. Neustálé opakování funkce se musí zařídit ve funkci samotné, proto je v naší funkci načítání čidla DHT11 realizováno v nekonečné smyčce.
A to je vlastně vše!
Funkce read_dht si běží ve svém vlákně, například čekací příkaz time.sleep(2), která zařizuje časování přístupu k pomalému čidlu DHT11, nikterak nebrzdí hlavní část programu, která obsluhuje webový server. V případě síťového dotazu ze strany nějakého klienta (např. webový prohlížeč vzdáleně se dotazující na stav čidla), dostane aktuální informaci prostřednictvím globálních proměnný temperature a humidity, které jsou v hlavním programu dostupné, ale aktualizovány jsou na pozadí funkcí read_dht.
V souvislosti s těmito globálními proměnnými si všimněme práce s těmito proměnnými v rámci jednotlivých funkcí. Python umožňuje vláknům sdílet proměnné, které jsou mimo lokální rozsah (např. globální proměnné), takže proměnné temperature a humidity, i když byly vytvořeny v jiném vlákně, jsou dostupné funkci read_dht().
Problém je však v přístupu k práci s těmi proměnnými. Pokud nějaká funkce má načíst nějakou proměnnou, podívá se do lokálního rozsahu, pokud tam taková funkce není, podívá se do rozsahu globálního. Takže v našem případě handle_request(),
když ve svém lokálním rozsahu nenajde proměnné temperature a humidity, najde je v rozsahu globálním a dokáže je odeslat ve své odpovědi. Jinak tomu je však v případě zápisu do těchto proměnných! Tím, že Python nemá výchozí deklaraci proměnných (jako známe například u jazyka Pascal, C apod.), dochází k deklaraci automaticky při prvním zápisu do dané proměnné. Jakmile se tedy ve funkci read_dht() pokusíme zapsat do proměnných temperature a humidity, a MicroPython tyto proměnné neobjeví v lokálním rozsahu, tak si je tam deklaruje. Tím pádem ale nezapisuje do rozsahu globálních proměnných skutečných (předem definovaných) proměnných temperature a humidity, ale právě vytvořených
lokálních, které ale nejsou funkci handle_request() přístupné. Musíme tedy při zápisu do proměnných temperature a humidity funkci read_dht() jasně říci, že se má zapisovat do proměnných z globálního rozsahu. To provedeme na začátku funkce read_dht() zápisem:
global temperature, humidity
Nyní tedy chápeme, proč ve funkci read_dht() musíme jasně říci, že proměnné temperature a humidity jsou globální, ale číst tyto proměnné ve funkci handle_request() můžeme i bez potřeby použití global. I když přidáním „deklarace“ global do funkce handle_request() bychom asi stejně nic nezkazili. 😊
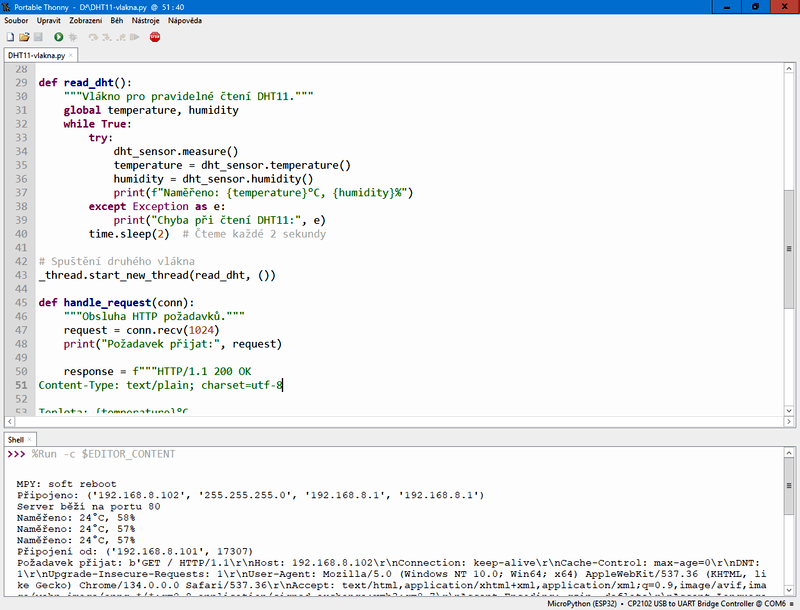
Výše uvedený příklad použití vlákna asi jasně ukazuje možnost použití vláken jako základního prvku multitaskingu. Jedná se vcelku o praktické použití, které poměrně hezky dokáže rozdělit nás program na dvě (skoro) vzájemně nezávislé úlohy, které běh programu výrazně zefektivní. Na druhou stranu je třeba se zamyslet, zda se jedná o jedinou možnost, jak tuto situaci vyřešit. Je také dobré zmínit, že použití _thread může být náročné na paměť, protože každé vlákno potřebuje svůj stack, takže je dobré se podívat, zda ještě neexistuje onen pověstný plán B.
B. Asynchronní programování (uasyncio)
V některých případech, například při práci s I/O operacemi (jako je komunikace přes sériový port nebo síť), může být
efektivnější využít asynchronní přístup s využitím modulu uasyncio. Modul uasyncio je lehká verze známého asyncio (používaného v běžném Pythonu) a je navržen pro asynchronní programování. Tento modul využívá kooperativní multitasking, což znamená, že jednotlivé úlohy sdílí jedno vlákno a předávají si řízení. Má to tu výhodu, že je tento způsob efektivnější
než _thread, protože nepotřebuje další systémové prostředky pro správu více vláken (menší spotřeba paměti). Obecně se říká, že se skvěle hodí pro síťové aplikace, práci s časovači nebo periodické čtení senzorů. A pravidelné čtení senzoru a síťová komunikace je přesně to, co v našem případě potřebujeme!
Obecný scénář našeho programu bude shodný s předchozím programem s vlákny:
- Vytvoříme (asynchronní) webový server.
- Budeme (asynchronně) číst data z DHT11.
- Server bude odpovídat na HTTP požadavky s aktuálními hodnotami teploty a vlhkosti.
Nyní se tedy pojďme podívat, co myslíme tím „asynchronně“.
Použití modulu uasyncio
Modul uasyncio v MicroPythonu slouží k implementaci asynchronního programování, což znamená, že umožňuje
běh více úkolů (tasks) současně, aniž by bylo nutné čekat na dokončení jednoho před tím, než začne další.
Hlavní funkce a výhody modulu uasyncio v MicroPythonu:
- Asynchronní úkoly: Umožňuje definovat úkoly, které běží nezávisle na sobě, aniž by blokovaly hlavní běh programu. To znamená, že můžeme mít více funkcí běžících současně (např. čekání na události, čtení ze senzorů, komunikace s jinými zařízeními…) bez toho, abychom museli používat náročná vlákna.
- Úspora prostředků: Modul je optimalizován pro mikrokontroléry s omezenými prostředky, takže je efektivní, co se týče paměti a výpočetního výkonu. Místo vlákna používá tzv. „tasky“, což jsou lehké asynchronní funkce, které nevyžadují mnoho systémových prostředků.
- Správa času a událostí: Umožňuje efektivní práci s časovými operacemi, jako je zpoždění (
sleep), časovače a opakované úkoly bez blokování hlavního programu.
Základní prvky modulu uasyncio:
uasyncio.: Spustí hlavní asynchronní úkol. Tato funkce obvykle spustí hlavní smyčku, která bude řídit všechny asynchronní úkoly.run() uasyncio.: Pauza v asynchronní funkci, která neblokuje celý program, ale pouze aktuální úkol.sleep() uasyncio.: Vytvoří nový úkol (task), který bude prováděn asynchronně.create_task() uasyncio.: Spojí více asynchronních úkolů do jednoho, aby bylo možné počkat na jejich dokončení.gather()
Trochu nám to připomíná modul _thread, nebo ne? Hlavní rozdíl mezi uasyncio a _thread je v tom, že uasyncio je asynchronní model, který nevyžaduje vlákna a neblokuje program, zatímco _thread skutečně vytváří více vláken, což znamená, že každý úkol běží na samostatném vlákně s vlastním časovým rozvrhem. Modul asyncio je pro ESP32 v MicroPythonu lepší volba než _thread, pokud nepotřebujeme skutečná paralelní vlákna (například pro zpracování složitých výpočtů).
Jak bude program našeho webového serveru s čidlem DHT11 vypadat v tomto pojetí? Podívejme se na následující ukázku proramu:
import network
import uasyncio as asyncio
from machine import Pin
from dht import DHT11
# Připojení k WiFi
SSID = "TvojeWiFi"
PASSWORD = "HesloWiFi"
sta_if = network.WLAN(network.STA_IF)
sta_if.active(True)
sta_if.connect(SSID, PASSWORD)
while not sta_if.isconnected():
pass
print("Připojeno:", sta_if.ifconfig())
# Nastavení DHT11
dht_pin = Pin(4) # Změníme na správný pin
dht_sensor = DHT11(dht_pin)
temperature = None
humidity = None
async def read_dht():
"""Asynchronní čtení DHT11."""
global temperature, humidity
while True:
try:
dht_sensor.measure()
temperature = dht_sensor.temperature()
humidity = dht_sensor.humidity()
print(f"Naměřeno: {temperature}°C, {humidity}%")
except Exception as e:
print("Chyba při čtení DHT11:", e)
await asyncio.sleep(2) # Čteme každé 2 sekundy
async def web_server(reader, writer):
"""HTTP server obsluhující požadavky."""
request = await reader.read(1024)
print("Požadavek přijat:", request)
response = f"""HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Teplota: {temperature} °C
Vlhkost: {humidity} %
"""
# Odeslání odpovědi
writer.write(response)
await writer.drain()
await writer.wait_closed()
async def main():
asyncio.create_task(read_dht11()) # Spustíme čtení DHT11 na pozadí
server = await asyncio.start_server(web_server, "0.0.0.0", 80)
print("Server běží na portu 80")
async with server:
await server.wait_closed() # Čekáme na ukončení serveru
# Spuštění programu
asyncio.run(main())
Program pochopitelně opět slouží k připojení k Wi-Fi síti, čtení hodnoty ze senzoru DHT11 a vytvoření jednoduchého webového serveru, který umožňuje uživatelům získat tyto hodnoty přes HTTP požadavky.
První část řeší připojení k existující Wi-Fi síti a touto částí se tedy nebudeme zabývat. Je připomeneme, že je potřeba do programu doplnit přístupové údaje k dané Wi-Fi síti.
Další část slouží načtení čidla DHT11. Je zde nejen nastavení signálového pinu (GPIO 4) a vytvoření objektu DHT, ale především asynchronní funkce read_dht11() pro čtení čidla. Za pozornost stojí dvě změny oproti standardnímu zápisu
funkce.
- Klíčové slovo
asyncpřed definicí funkce - Klíčové slovo
awaitpřed příkazem čekáníasyncio.sleep(2)
Zkusíme si obojí vysvětlit najednou.
Co znamená await v asynchronní funkci?
V asynchronním programování jsou funkce označené jako async považovány za asynchronní. To znamená, že
tato funkce vrátí jakýsi úkol (task), který bude vykonán později, bez blokování hlavního vlákna programu. Funkce tedy nebude vykonána hned, ale bude zapsána do „čekací fronty“ a bude provedena až ve chvíli, kdy na ni bude čas. Asynchronní funkce tedy běží nezávisle na hlavním programu a může v určitou chvíli „spadnout“ zpět do čekací fronty, což umožňuje provádět jiné úlohy.
awaitje klíčové slovo, které se používá k tomu, aby se čekalo na dokončení asynchronní operace. Když se použijeawait, říká to Pythonu: „Počkej na dokončení této operace, ale během čekání umožni jiným úkolům běžet.“
Pokud tedy ve funkci read_dht11() použijeme await asyncio., znamená to, že program čeká 2 sekundy (jak je požadováno), ale během této doby neblokuje celý program. Místo toho může běžet jiný kód (například
obsluhování webových požadavků nebo jiných úkolů, které běží souběžně).
Pokud bychom místo await asyncio. použili jen asyncio.sleep(2) bez await,
došlo by k tomu, že funkce read_dht11() by nebyla asynchronní. To znamená, že by se stala blokující. To je důvod, proč je await tak důležité – aby asynchronní funkce zůstala asynchronní a během čekání mohla pokračovat v jiných operacích
Chápeme-li deklaraci funkcí async (a klíčové slovo await), můžeme se podívat na funkci řešící webový server, tj. web_server()
Při pohledu na kód zde asi máme tradiční odbavení dotazu klienta. To, co je zde nové a možná i zarážející jsou následující řádky:
await writer.
await writer.
Proč await writer.drain()?
Metoda drain() je specifická pro asynchronní operace a slouží k tomu, aby se zaručilo, že data byla skutečně odeslána do síťového bufferu a že je k dispozici místo pro zápis dalších dat.
Pokud používáme asynchronní zápis (např. write()), nemusí být data okamžitě odeslána na síť. Data jsou často zapsána do bufferu, což znamená, že je tam „čekající“ obsah, který ještě nebyl odeslán do cílového zařízení. Metoda drain() říká Pythonu, že se má počkat, dokud nebude buffer vyprázdněn. Kombinace await writer. tedy čeká, dokud nebude možné pokračovat v zápisu dalších dat nebo dokud nebude buffer plně odeslán. V praxi to znamená, že drain() pomáhá zabránit přetížení bufferu při odesílání dat a zajišťuje, že případné další zápisy budou bezpečně provedeny až po dokončení předchozích operací zápisu. Bez await writer. by mohl být buffer přetížený a data by nebyla správně odeslána, což by vedlo k problémům při komunikaci.
Proč await writer.wait_closed()?
Metoda wait_closed() je použita k tomu, aby počkala, dokud bude stream (např. socket) skutečně uzavřen. Po write() chceme, aby spojení bylo korektně uzavřeno, než program skončí. Příkaz await writer. čeká, dokud nebude spojení řádně uzavřeno, což může zahrnovat interní čištění a odeslání posledních dat. Tato metoda je užitečná pro zabezpečení, že všechny operace se streamem byly dokončeny a že není žádný otevřený socket nebo neodeslaná data, která by způsobila chyby nebo problémy v komunikaci.
Proč jsou drain() a wait_closed() asynchronní (s await)?
Příkaz write() je rychlá operace, která nevyžaduje čekání. I když data možná nejsou okamžitě odeslána na síť, write() neblokuje běh programu a pokračuje dál. Na druhé straně drain() a wait_ jsou operace, které vyžadují čekání, dokud není zajištěno, že všechny předchozí operace zápisu byly dokončeny a že síťové připojení je správně uzavřeno. Bez použití await by program pokračoval bez záruky, že všechna data byla skutečně odeslána nebo že spojení bylo správně uzavřeno. await u těchto metod zajišťuje, že program počká, dokud se operace správně neukončí.
Poslední částí je funkce main(), která je klíčová pro spuštění asynchronního serveru a spuštění čtení hodnot z DHT11 senzoru.
Její první řádek:
asyncio.
spustí funkci read_dht11() na pozadí. Funkce read_dht11() je také asynchronní, což znamená, že její vykonání nebude blokovat běh dalších částí programu. Metoda create_ vytvoří nový asynchronní úkol, který bude provádět funkci read_dht11() paralelně s hlavním programem. Funkce read_ pravidelně čte hodnoty z DHT11 a aktualizuje globální proměnné temperature a humidity. Tento úkol běží na pozadí, protože nečeká na jeho dokončení, pokračuje se v dalším kódu v main().
Následující řádka:
server = await asyncio.
spustí asynchronní HTTP server. Místo toho, abychom přímo používali nízkoúrovňový modul usocket (který by vyžadoval explicitní vytváření, připojování a spravování socketů), asyncio. abstrahuje tyto kroky a umožňuje soustředit se na logiku obsluhy požadavků (tedy jak reagovat na HTTP požadavky a jaké odpovědi posílat). Jinými slovy: Když použijeme asyncio., vytváříme rovnou server, který automaticky spravuje příchozí připojení a volá vaši funkci pro obsluhu požadavků. Nastavená funkce obsluhy požadavků web_ reaguje na požadavky, které server přijme. Funkce čte data pomocí reader. a odpovídá pomocí writer.. Takto nastavený server bude naslouchat na IP adrese "0.0.0.0" (což znamená, že server bude dostupný na všech síťových rozhraních zařízení) a na portu 80, což je standardní port pro HTTP server. Funkce await znamená, že program počká, dokud nebude server skutečně spuštěn. Až pak bude pokračovat k dalšímu kroku. Tento krok však neblokuje celý program, protože používá asynchronní přístup, takže i když server čeká na připojení, jiný kód (zde čtení DHT11) může běžet paralelně. Jakmile je server úspěšně spuštěn, provede se další příkaz – vypíše se na konzolu, že server je připraven přijímat požadavky.
Na závěr je v programu poměrně zvláštní konstrukce:
async with server:
await server.
Příkaz async with je způsob, jak správně spravovat asynchronní prostředky (v tomto případě server). Tato syntaxe znamená, že server se bude spouštět a běžet, dokud nebude explicitně zastaven. Server zůstává stále otevřený a čeká na nové požadavky. Pokud by došlo k nějaké chybě nebo by bylo potřeba server vypnout, automaticky dojde k uzavření serveru. Pokud by se server musel ukončit, provedou se potřebné závěrečné operace.
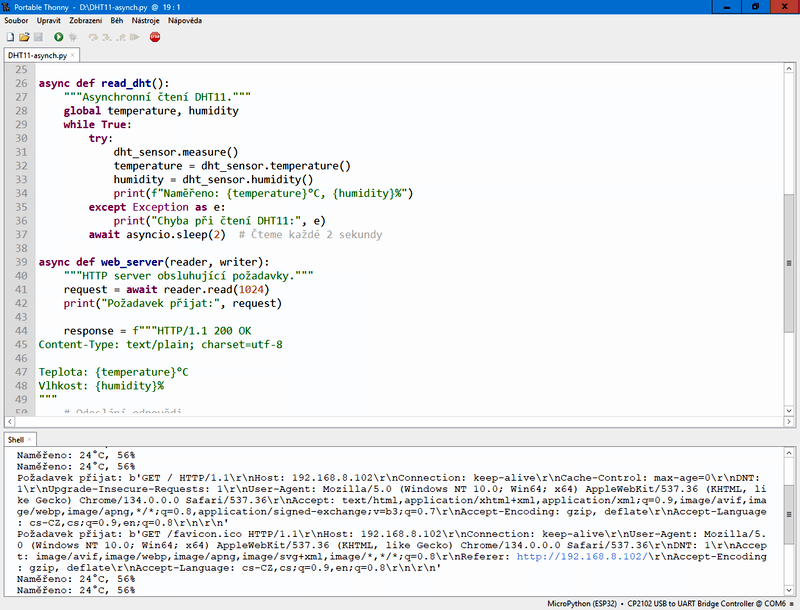
Použitý přístup umožňuje spouštět více úkolů současně, což je výhoda asynchronního programování – vše běží efektivně bez blokování hlavní smyčky programu.
Shrnutí používání multitaskingu na modulu ESP32 v MicroPythonu
V MicroPythonu pro ESP32 lze multitasking realizovat dvěma hlavními způsoby: pomocí modulu _thread pro práci s vlákny a pomocí modulu uasyncio pro asynchronní programování. Tyto dvě metody mají různé přístupy a výhody, a každá z nich je vhodná pro různé scénáře.
Použití modulu _thread
Modul _thread je určen pro práci s vlákny, což je základní metoda multitaskingu, kdy každé vlákno běží nezávisle na ostatních. V MicroPythonu na ESP32 ale multitasking pomocí _thread nevyužívá skutečné vícevláknové zpracování (nebo je velmi omezené), protože v MicroPythonu pro ESP32 není podpora pro souběžný multitasking na dvou jádrech.
Výhody a nevýhody _thread na ESP32:
Výhody:
- Vhodné pro určité úkoly, které je potřeba vykonávat na pozadí, například čtení dat z různých senzorů.
- Může být užitečné pro úkoly, které příliš nevyžadují interakci nebo synchronizaci mezi vlákny.
Nevýhody:
- Na ESP32 je podpora více vláken omezená (i když může běžet více vláken, skutečný vícejádrový multitasking není podporován).
- Synchronizace mezi vlákny není jednoduchá a může vést k problémům s přístupem ke sdíleným prostředkům (používání zámků
_thread.je nutné).allocate_ lock()
Použití modulu uasyncio
Tento přístup nevyžaduje skutečná vlákna, ale místo toho využívá asynchronní úkoly (tasks) a čekací mechanizmy, jako je await, pro řízení, které úkoly se vykonávají a kdy. Modul uasyncio je velmi efektivní, protože umožňuje běh více úkolů v rámci jediné smyčky bez skutečného multitaskingu na úrovni vláken. To znamená, že místo toho, aby každý úkol běžel na vlastním vlákně, všechny úkoly běží v jedné smyčce, ale díky tomu, že asynchronní úkoly používají await, se zdá, že běží současně. ESP32 může efektivně využívat uasyncio, protože zajišťuje nízkou režii při práci s více úkoly.
Výhody a nevýhody uasyncio na ESP32:
Výhody:
- Má nízkou režii, protože nevyžaduje spravování více vláken, což je ideální pro mikrořadiče s omezenými prostředky.
- Umožňuje současné vykonávání více úkolů bez zbytečné složitosti.
Nevýhody:
- Je omezený pro úkoly, které jsou závislé na vstupu/výstupu, protože výpočetně náročné úkoly nejsou pro
uasyncioefektivní. - U složitějších scénářů může být těžší ladit, protože asynchronní kód může být obtížnější na sledování.
Tabulka srovnání modulu _thread a uasyncio na ESP32
| Funkce | Modul _thread |
Modul uasyncio |
|---|---|---|
| Základní princip | Vlákna, každé běží paralelně (i když na jediném jádře). | Asynchronní úkoly (tasks), vše běží v jedné smyčce. |
| Multitasking | Na modulu ESP32 simulovaný multitasking na jediném jádře. | Simulovaný multitasking v jedné smyčce. |
| Jednoduchost | Použití vláken pro jednoduché paralelní úkoly. | Efektivní pro I/O úkoly, ale složitější kód. |
| Dopad na výkon | Více vláken může vést k vyšší režii (především na paměť). | Nízká režie, ideální pro zařízení s omezenými prostředky. |
| Použití | Pro úkoly, které mají běžet paralelně na pozadí. | Pro asynchronní I/O operace, jako je čtení senzorů nebo komunikace. |
Závěr
V dnešním článku jsme si představili dvě základní možnosti multitaskingu na modulu ESP32 při programování v MicroPythonu. Při volbě mezi těmito dvěma přístupy bychom měli zvážit, jaký typ úkolů náš program vykonává. Pokud se jedná o čtení senzorů, komunikaci po síti a podobné operace, které nejsou výpočetně náročné, je většinou modul uasyncio lepší volbou. Ale jak jsme v případě našeho jednoduchého měřicího webového serveru viděli, pro jednodušší paralelní úkoly můžeme dost dobře použít i modul _thread.
Dnes to asi zase bylo až příliš „akademické“, v příštích článcích se tedy opět trochu vrátíme k našemu původnímu záměru, a to psát základní seznámení s MicroPythonem na modulu ESP32. Pustíme se do jednoduchých ukázek ovládání a načítání různých čidel, jako jsou další meteorologická čidla, sonarový dálkoměr, ovládání serva a podobně.